Improve RAG Systems for AI Answer Engines: A Systematic Diagnosis Framework
Cover Image
Most RAG tutorials tell you what to build. This guide tells you what's breaking it.
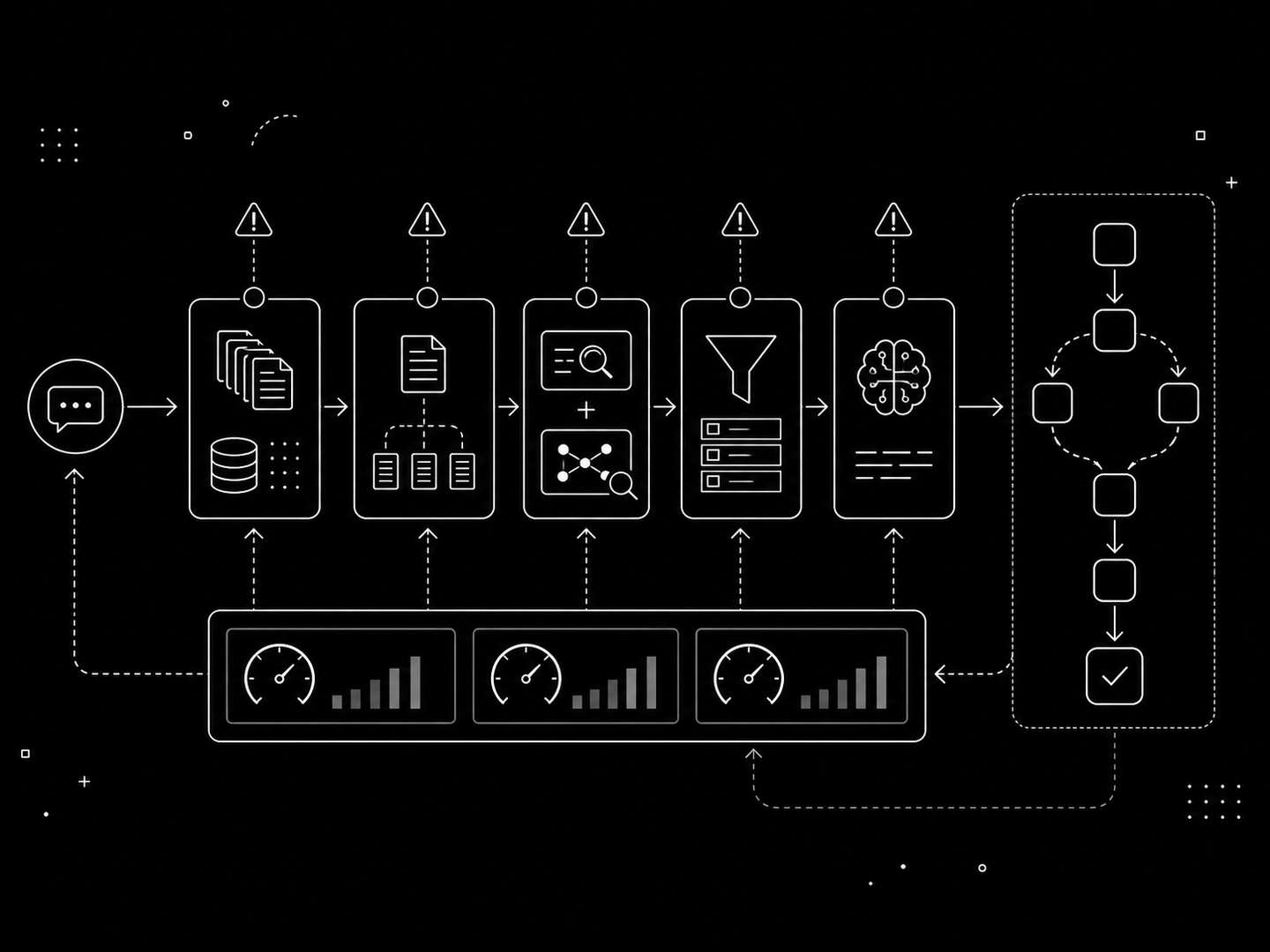
You've seen the pattern: a team spins up a RAG pipeline, feels good about the first results, ships it — then watches in confusion as accuracy drifts, hallucinations creep in, and retrieval starts returning plausible-but-wrong chunks. The problem isn't that RAG doesn't work. It's that nobody diagnosed which failure mode is destroying their accuracy before reaching for a fix.
RAG systems fail in predictable ways. Once you know the patterns, you stop guessing and start fixing what's actually broken. Here's the framework.
The Five Failure Modes of RAG Systems
Before you can fix anything, you need to know what's broken. RAG failures cluster into five distinct categories — and most teams are fighting the wrong one.
1. Retrieval returns irrelevant or off-topic chunks
The semantic search finds something, but that something doesn't answer the user's question. The model generates a confident, well-structured answer — built on the wrong foundation.
2. Retrieved context contradicts the model's knowledge
The model has strong pre-training beliefs that clash with what retrieval surfaces. It sometimes overrides retrieved evidence, especially when the chunk format is ambiguous.
3. Hallucination from weak retrieved signal
Retrieval returns nothing useful, but the model still generates an answer rather than saying "I don't know." This is the silent killer — outputs look reasonable until you spot the factual errors.
4. The retrieval step never fires when it should
In agentic pipelines, the LLM decides when to search. Sometimes it skips retrieval entirely on questions that clearly need external knowledge. This is an agent-computer interface (ACI) failure — your tools aren't designed clearly enough for the model to use them correctly.
5. No evaluation baseline — you can't tell if you're improving
You change chunk sizes, swap embedding models, add a reranker — and you have no way to know if any of it made things better or worse. Without a measurement loop, you're guessing.
Once you've identified which mode(s) apply to your system, the fixes below target each one directly.
The Evaluation Foundation: Measure Before You Fix
Never optimize a RAG system blind. Build a measurement loop first — every change you make needs a before/after signal, or you're just shuffling heuristics.
Ground truth evaluation sets are the starting point. Assemble 50–100 query/answer pairs that represent real user questions — not synthetic tests, actual production queries with known correct answers. Run your pipeline against them and measure:
Context precision — did the retrieved chunks actually contain the answer?
Answer faithfulness — does the generated answer stay true to the retrieved context?
Answer relevance — does the answer actually address what was asked?
RAGAS (RAG Assessment Suite) provides automated metrics for all three. You don't need human ratings for every iteration — RAGAS gives you a fast, cheap signal to iterate against.
# RAGAS evaluation snippet (conceptual)
from ragas import evaluate
from datasets import Dataset
# Your eval dataset: question, answer, contexts, retrieved_contexts
dataset = Dataset.from_dict({...})
result = evaluate(dataset, metrics=[context_precision, faithfulness, answer_relevance])
LangSmith tracing lets you inspect the full retrieval sequence: which chunks were retrieved, what the latency was at each step, and where generation diverged from the retrieved signal. For agentic RAG, this is how you catch retrieval steps that should have fired but didn't.
Set a baseline before making any pipeline changes. Without it, you won't know if that reranker actually helped or if you're just feeling more confident about outputs that are equally wrong.
RAGAS provides automated evaluation metrics you can integrate into CI pipelines — context precision, faithfulness, and answer relevance — without needing human raters on every iteration. Pair it with LangSmith for production tracing and you have a full measurement stack without building it from scratch.
Chunking That Actually Works
Chunking strategy has an outsized effect on retrieval quality — and it's the step most teams rush through with default settings.
RecursiveCharacterTextSplitter is the standard starting point. It respects language boundaries (sentences, paragraphs) rather than cutting at arbitrary character offsets, which keeps semantic units intact. A typical config looks like:
from langchain.text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # adjust based on your embedding model's context window
chunk_overlap=200, # overlap preserves cross-chunk context
add_start_index=True # trace chunks back to source documents
)
Choosing chunk size by data type:
Data type | Recommended chunk size | Why |
|---|---|---|
Code / API docs | 256–512 tokens | Dense semantic units, small context windows |
Long-form articles | 800–1200 tokens | Balance coverage vs. noise |
Structured data (JSON, tables) | 64–256 tokens | Preserve row/cell-level semantics |
Conversational Q&A | 256–512 tokens | Short, independent semantic units |
Overlapping chunks (200–300 token overlap) prevents context from being split mid-thought. Without overlap, a question whose answer spans two chunks will retrieve neither fully.
Track provenance — when you retrieve a chunk, you need to be able to trace it back to the source document. Set add_start_index=True so you can reconstruct document context at retrieval time. This matters for citations and for debugging where wrong answers are coming from.
The goal: each chunk should be independently meaningful. A chunk that only makes sense in the context of the previous 400 tokens is a chunk that will fail retrieval.
Hybrid Search + Reranking: From Plausible to Relevant
Semantic (dense vector) search catches conceptual matches that keyword search misses. But it also returns chunks that are conceptually related but not actually relevant to the specific query. Hybrid search bridges the gap.
Combine dense + sparse retrieval. Dense vectors handle natural language variation ("how do I configure..." matches "setting up...") while sparse lexical search handles domain-specific terminology (product names, acronyms, exact codes). Together they cover more of the relevance spectrum:
# Conceptual hybrid search (pseudo-implementation)
dense_results = vector_store.similarity_search(query, k=20)
sparse_results = bm25_retriever.get_relevant_documents(query, k=20)
# Merge with reciprocal rank fusion (RRF)
merged = rrf_fusion(dense_results, sparse_results, k=60)
Reciprocal Rank Fusion (RRF) scores each document by its rank in both result sets, avoiding the dominance of whichever retrieval method has a longer retrieval list.
After hybrid search, add a cross-encoder reranker. The reranker takes the query + candidate document pair and scores relevance directly — not by embedding similarity, but by whether this specific query is answered by this specific chunk. Cohere's Rerank or a fine-tuned cross-encoder delivers the biggest single accuracy jump in most RAG pipelines.
The output: retrieval that returns not just semantically plausible chunks, but actually relevant ones.
Agentic RAG for Complex, Multi-Hop Questions
Simple two-step retrieval chains — query → semantic search → generate — work well for straightforward questions. But complex, multi-hop questions expose their limits. "What changed in our Q3 reporting requirements and how does that affect data pipeline compliance?" requires multiple searches, synthesis across sources, and iterative refinement.
Agentic RAG handles this by giving an LLM agent control over the retrieval process. The agent decides:
How many searches to run
What sub-questions to decompose the original query into
Whether retrieved context is sufficient before generating
When to refine a search with a reformulated query
# Agentic RAG orchestration (conceptual)
from llama_index.core import SimpleComposableRetrieval
# Agent decides tool use dynamically
agent = OpenAIAgent.from_tools(
query_engine_tools=[vector_retriever, bm25_retriever, knowledge_graph],
verbose=True
)
response = agent.chat("complex multi-hop question")
LlamaIndex provides the agentic orchestration layer for this pattern — its agent abstraction handles tool selection, query decomposition, and iterative retrieval out of the box.
Query decomposition is the key pattern. Break a complex question into sub-questions, retrieve for each, then synthesize. "What changed in our Q3 reporting requirements" retrieves for requirements; "how does that affect data pipeline compliance" retrieves for compliance; the agent combines both.
When to use chains vs. agents:
- Simple, constrained queries → two-step chains (lower latency, predictable)
- Open-ended, multi-concept questions → agents (handles iterative retrieval, knows when to stop)
Test your system against multi-hop questions specifically. If single-shot retrieval handles your benchmark questions well but complex queries still hallucinate, that's your signal to move to an agentic architecture.
Security and Reliability: Prompt Injection and Context Overflow
Two RAG-specific failure modes don't get enough attention.
Indirect prompt injection via retrieved documents. A document in your vector store can contain text that, when included in the model's context window, instructs it to behave differently than your system prompt intended. Since retrieved text shares the same context window as your instructions, embedded instructions can be followed without being obviously malicious — they look like part of the task.
Mitigations:
- Defensive prompts: explicitly instruct the model to treat retrieved context as data only and ignore any embedded instructions that look like directives
- Structural delimiters: wrap retrieved content in XML tags (...) so the model can distinguish data from instructions
- Output validation: check that the model's response matches expected format before returning it
Context overflow occurs when retrieved chunks exceed the model's context window. For long documents, models struggle to locate relevant information inside very long inputs — even if that information was retrieved correctly.
Chunk strategically (see above), and set a hard cap on the total context sent to the generation model. If retrieval returns more chunks than fit in context, prioritize by relevance score and log the truncation so you know it happened.
The Iteration Loop: Monitoring and Improving in Production
RAG isn't a one-time build. Your vector index reflects your data at a point in time — as source documents update, your index staleness becomes a source of accuracy drift.
Keep the vector index fresh. Set up incremental indexing so that when source documents change, the vector store reflects those changes within hours, not weeks. For high-stability domains (legal, compliance, medical), consider a weekly full reindex.
Track retrieval vs. generation failures separately. A wrong answer can come from retrieval returning bad chunks, or from generation ignoring good chunks. Measure them independently — context precision tells you about retrieval quality; answer faithfulness tells you about generation behavior.
When to escalate to fine-tuning. If your evaluation loop shows consistent failure patterns that no retrieval strategy fixes — the model keeps misunderstanding your domain terminology, or its reasoning style doesn't match your use case — that's the signal to invest in fine-tuning. Fine-tuning addresses generation quality issues that retrieval optimization cannot. But it's expensive and slow. Don't reach for it until you've exhausted retrieval improvements.
Measure everything. Change one thing at a time. Measure again. Improving RAG systems is an iterative discipline — the teams that get reliable results are the ones who stop guessing and start diagnosing. That's the only path to a RAG system that actually answers questions reliably.